

🎙️ Conversational AI has improved dramatically over the past few years, yet most voice systems still feel unnatural. Users pause. The assistant waits. Responses arrive late. Interruptions break the flow.
PersonaPlex changes this.
PersonaPlex is a full-duplex conversational AI model designed to listen and speak at the same time, enabling fluid, human-like dialogue rather than turn-based command execution. Instead of treating speech recognition, reasoning, and speech generation as separate steps, PersonaPlex unifies them into a single real-time system.
This architectural shift places PersonaPlex at the center of a broader transition toward modern AI agent architectures, where intelligence is continuous, contextual, and interactive rather than reactive.
👉 Related insight: modern AI agent architectures
🧠 What Is PersonaPlex?
PersonaPlex is a speech-to-speech conversational AI model capable of:
processing live audio input continuously
generating spoken responses while still listening
handling interruptions naturally
maintaining conversational context mid-utterance
expressing backchannels like “mm-hmm” or “right”
Unlike traditional voice assistants, PersonaPlex does not “wait its turn.” It operates in full duplex, the same way humans do during real conversations.
The model is based on NVIDIA’s research work and is available through open tooling and forks such as the PersonaPlex repository you referenced, making it accessible for experimentation, prototyping, and research-driven applications.
🔄 Why Traditional Voice AI Still Feels Robotic
To understand why PersonaPlex matters, it helps to understand what came before it.
Traditional Voice AI Pipeline
Most voice assistants still rely on a cascaded pipeline:
Automatic Speech Recognition (ASR)
Text processing via an LLM
Text-to-Speech (TTS) synthesis
Each step must complete before the next begins. This introduces:
noticeable latency
unnatural pauses
inability to interrupt
delayed feedback
poor conversational rhythm
Even with powerful models, the architecture itself limits realism.
PersonaPlex removes this bottleneck by collapsing the pipeline into a single, continuously operating model.
⚙️ Full-Duplex Conversational Architecture
PersonaPlex is built on a dual-stream Transformer architecture that processes incoming and outgoing audio simultaneously.
Key Architectural Characteristics
Streaming audio tokens instead of discrete utterances
Shared contextual state for listening and speaking
Low-latency generation (often under 300 ms)
Overlapping speech support
Continuous turn-taking
This design enables real conversation rather than command-response interaction.
Importantly, this capability comes at a cost — one that directly connects PersonaPlex to the AI infrastructure boom in 2026.
👉 Strategic context: AI infrastructure boom in 2026
🧩 Persona Control: More Than Just Voice
One of PersonaPlex’s most powerful features is persona conditioning.
PersonaPlex allows developers to shape how the model behaves, not just what it says.
Persona Layers
System prompt – rules, safety, constraints
Text persona – role, expertise, tone
Voice prompt – timbre, pace, emotion
This multi-layer approach enables:
branded assistants
role-specific agents (support, sales, education)
consistent voice identity
emotional nuance without scripting
This design philosophy closely mirrors trends seen in AI orchestration platforms like OpenClaw, where multiple intelligent components work together under shared control logic rather than acting independently.
👉 Related reading: AI orchestration platforms like OpenClaw
🛠️ The PersonaPlex GitHub Repository (What It Offers)
The PersonaPlex repository you referenced is a forked implementation designed for experimentation and local deployment.
What Developers Typically Find Inside
Python-based server logic
Streaming audio pipelines
Persona configuration files
Voice conditioning examples
Docker and environment setup
Client demos for browser or local use
This makes PersonaPlex suitable for:
research environments
advanced prototypes
internal tooling
voice-first product exploration
While production deployment requires careful engineering, the repository provides a strong foundation for hands-on experimentation.
📉 Latency, Cost, and Infrastructure Reality
Running full-duplex conversational AI is computationally expensive.
PersonaPlex depends on:
GPU-accelerated inference
low-latency networking
continuous audio streams
sustained compute availability
These requirements directly intersect with real-time AI infrastructure challenges such as GPU scarcity, rising cloud costs, and power constraints — all defining features of the current AI landscape.
👉 Deeper analysis: real-time AI infrastructure challenges
Why This Matters Strategically
Costs scale with usage, not users
Latency depends on geographic placement
Poor architecture leads to unpredictable bills
Infrastructure decisions become product decisions
PersonaPlex is powerful — but only when deployed thoughtfully.
🎯 Where PersonaPlex Makes Sense (And Where It Doesn’t)
Strong Fit
customer support voice agents
conversational tutors
immersive gaming NPCs
AI companions
enterprise voice workflows
Weak Fit
simple voice commands
low-power edge devices
latency-tolerant workflows
one-shot interactions
PersonaPlex shines where conversation quality matters more than raw throughput.
🧠 PersonaPlex in the Context of AI Systems Design
PersonaPlex is not an isolated breakthrough. It represents a broader shift:
From:
“Ask → Wait → Answer”
To:
“Listen → Respond → Adapt → Continue”
This same shift underpins next-generation AI systems built around autonomy, coordination, and continuous perception — not static prompts.
👉 Strategic overview: next-generation AI systems
Voice is simply the most visible interface where this change becomes obvious.
🧪 Implementation Considerations (Hard Lessons)
Before adopting PersonaPlex-style systems, teams should plan for:
Usage limits to control cost
Fallback logic if inference fails
Observability for real-time streams
Security controls for audio data
Human-in-the-loop escalation paths
Conversational AI is not “set and forget.” It requires operational maturity.
🧭 Strategic Takeaway for Businesses
PersonaPlex demonstrates what’s possible — not what’s mandatory.
The real lesson is not “add voice AI,” but:
Design AI systems that feel continuous, contextual, and responsive.
Organizations that succeed treat conversational AI as part of an end-to-end AI implementation, integrating architecture, deployment, monitoring, and iteration into a single strategy.
👉 Execution mindset: end-to-end AI implementation
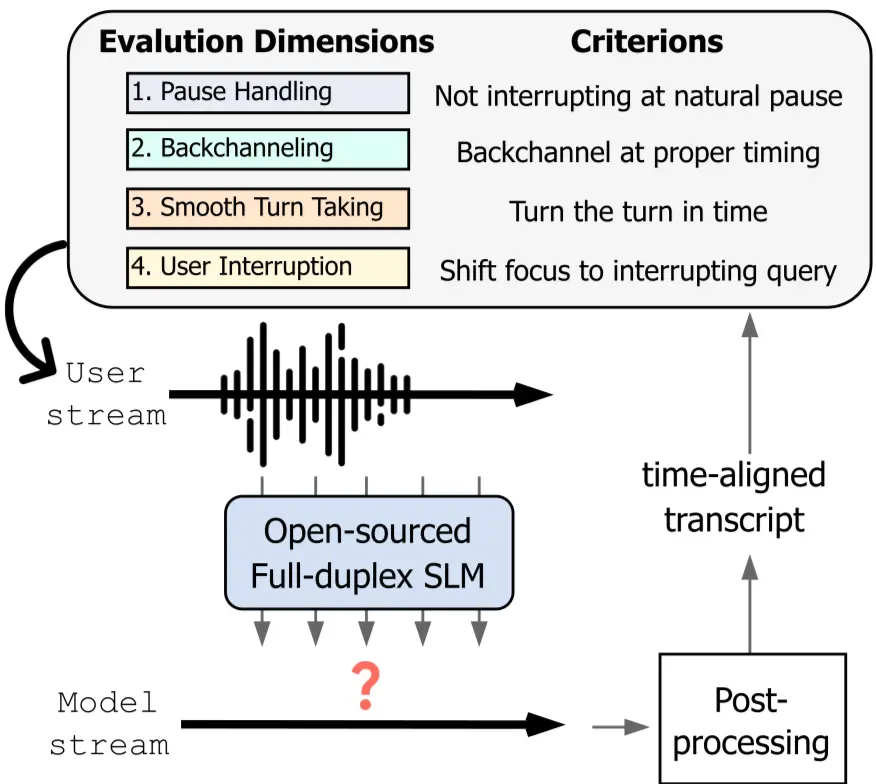
🧠 Traditional Voice AI vs PersonaPlex (Visual Comparison)
| Feature | Traditional Voice AI | PersonaPlex |
|---|---|---|
| Architecture | ASR → LLM → TTS (cascade) | Unified full-duplex model |
| Latency | 800–2000 ms | ~200–300 ms |
| Interruptions | ❌ Not supported | ✅ Native |
| Turn-taking | Artificial pauses | Natural overlap |
| Backchannels | ❌ None | ✅ “uh-huh”, “right” |
| Persona control | Limited | Advanced (voice + text) |
🔄 PersonaPlex Architecture (Conceptual Flow)
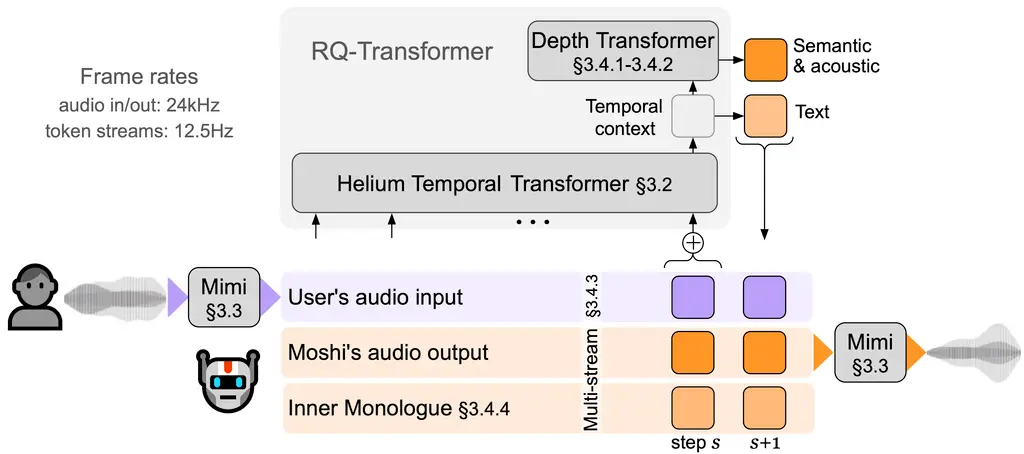
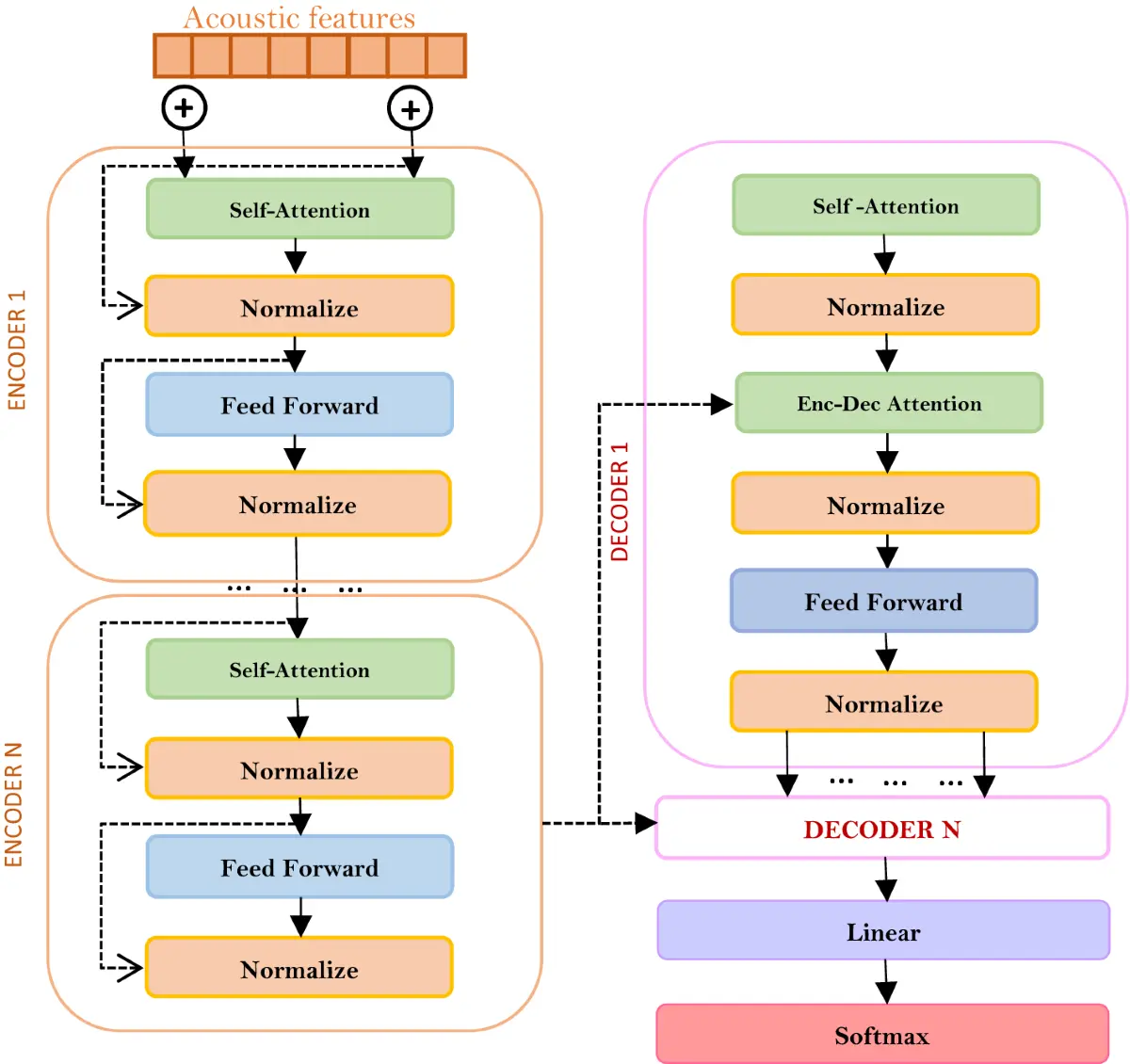
PersonaPlex uses a dual-stream Transformer, where:
Incoming audio is continuously encoded
Outgoing speech is generated at the same time
Context is updated mid-utterance
The model never “waits” for the user to finish speaking
This is why PersonaPlex feels conversational instead of reactive.
🧩 Persona & Prompting Model

PersonaPlex supports multi-layer conditioning:
🎭 Persona Layers
System prompt – rules, safety, constraints
Text persona – role, tone, expertise
Voice prompt – timbre, emotion, rhythm
This makes PersonaPlex ideal for:
branded assistants
enterprise agents
NPCs and companions
education and training tools
🧑💻 Code Examples (Developer-Friendly)
▶️ Example: Starting PersonaPlex Server
export HF_TOKEN=your_huggingface_token
python server.py --model personaplex-7b-v1
What this does:
Authenticates model access
Loads PersonaPlex weights
Starts a real-time streaming server
🎙️ Example: Defining a Persona (Text Prompt)
{
"persona": {
"role": "Technical AI advisor",
"tone": "calm, precise, professional",
"style": "short, confident explanations",
"audience": "developers and CTOs"
}
}
🔊 Example: Voice Conditioning (Conceptual)
voice_prompt:
base_voice: "neutral_male_01"
pitch: medium
tempo: natural
emotion: subtle_confidence
This allows voice identity consistency, which is critical in:
customer service
training
branded AI products
📈 When PersonaPlex Is the Right Choice (Decision Table)
| Use Case | PersonaPlex Fit |
|---|---|
| Customer support calls | ⭐⭐⭐⭐⭐ |
| Voice assistants | ⭐⭐⭐⭐⭐ |
| Gaming NPCs | ⭐⭐⭐⭐⭐ |
| Call centers | ⭐⭐⭐⭐ |
| Simple voice commands | ⭐⭐ |
| Low-resource devices | ⭐⭐ |
If you want deeper strategic and technical insight, explore:
OpenClaw Guide 2026 — AI agent orchestration
AI Infrastructure Boom 2026 — compute, power, and cloud economics
More LogaTech AI insights — automation, systems, and digital strategy
❓ FAQ
What makes PersonaPlex different from chatbots?
PersonaPlex is a speech-to-speech system that listens and speaks simultaneously, enabling real conversation instead of turn-based interaction.
Is PersonaPlex production-ready?
It is research-grade and suitable for advanced prototypes. Production use requires careful infrastructure and cost planning.
Does PersonaPlex replace LLMs?
No. It integrates reasoning directly into a speech-centric architecture rather than relying on separate text pipelines.
Is full-duplex conversational AI the future?
Yes — especially for voice, education, gaming, and support use cases where interaction quality matters.
